AI奇点网6月28日报道 | 微软研究人员在人工智能领域的创新之一是ZeRO++,一种旨在优化大型模型训练的系统。大规模模型如Turing-NLG、ChatGPT和GPT-4的训练需要跨多个GPU设备的大量内存和计算资源。为了克服ZeRO在小批量和低带宽集群训练中的限制,DeepSpeed团队开发了ZeRO++,它在现有的ZeRO优化基础上引入了增强的通信策略。

ZeRO系列优化使用集体GPU内存和计算能力进行模型状态的跨GPU划分,而不是复制。然而,在训练过程中,ZeRO可能会导致较高的通信开销。为了解决这个问题,ZeRO++结合了三个通信优化策略:量化权重通信(qwZ)、分层权重划分(hpZ)和量化梯度通信(qgZ)。
ZeRO++采用了权重量化,利用基于块的量化来降低参数通信量,并保持训练精度。通过在每台机器内维护完整的模型副本来交换GPU内存进行通信,最大限度地减少了反向传播期间的通信开销。对于梯度通信,ZeRO++引入了qgZ,一种新颖的量化梯度通信范例,可以减少跨节点流量和延迟。

这些通信优化使通信量显著减少,ZeRO++相较于ZeRO的减少量可达到4倍,从而提高了训练吞吐量和效率。当每个GPU使用小批量大小时,在高带宽集群中,ZeRO++的吞吐量比ZeRO-3提高了28%到36%。与ZeRO-3相比,ZeRO++在低带宽集群中平均加速了2倍,使得大型模型训练更容易在更广泛的集群中进行。
除了训练场景,ZeRO++还可以扩展到使用人类反馈(RLHF)训练的强化学习对话模型中。通过与DeepSpeed-Chat的集成,RLHF训练可以受益于改进的生成和训练阶段,实现比ZeRO更高的生成吞吐量(高出2.25倍)和训练吞吐量(高出1.26倍)。

DeepSpeed发布了ZeRO++,使得大型模型训练更加高效,并可供AI社区使用。这一系统旨在加速训练、减少通信开销,并实现更大的批量,最终节省时间和资源。研究人员和从业者可以利用ZeRO++更有效地训练ChatGPT等模型,并探索人工智能的新可能性。

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过 AI视频后期消除对象神器ProPainter:一涂一抹,视频轻松移除指定对象丨本地离线一键部署
AI视频后期消除对象神器ProPainter:一涂一抹,视频轻松移除指定对象丨本地离线一键部署
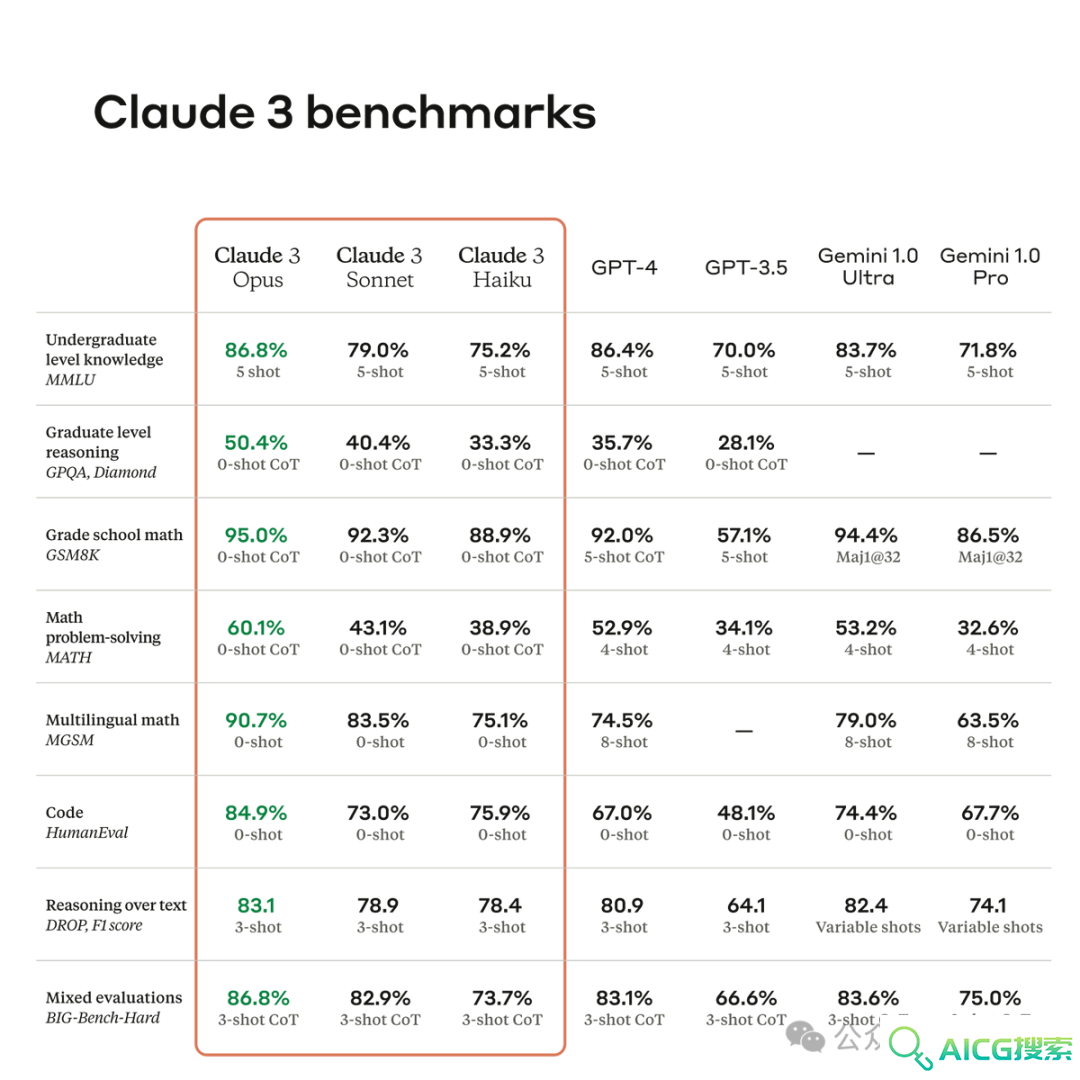 大语言模型「新王」Claude 3全面测评:原生多模态大模型各项能力实力超群,连打麻将都学会,实测比GPT-4好用
大语言模型「新王」Claude 3全面测评:原生多模态大模型各项能力实力超群,连打麻将都学会,实测比GPT-4好用
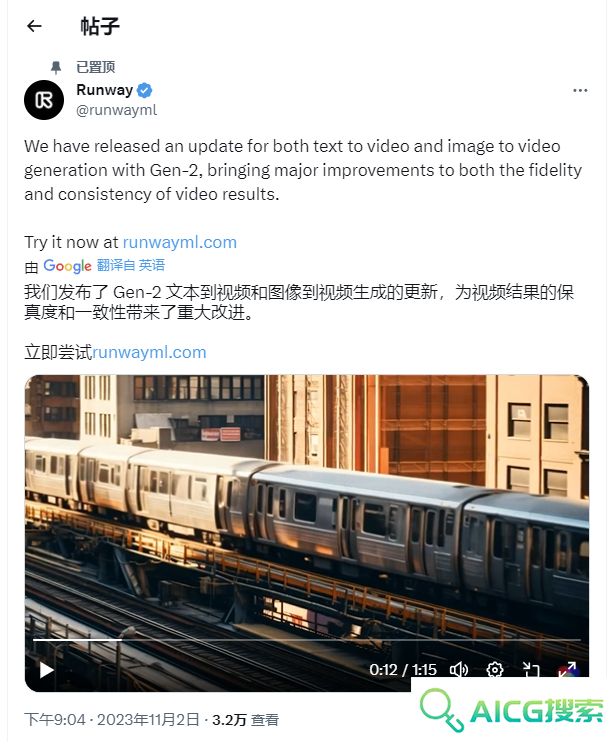 Runway Gen-2史诗级版本更新实测:我宣布,AI视频迎来「iPhone时刻」
Runway Gen-2史诗级版本更新实测:我宣布,AI视频迎来「iPhone时刻」
 特斯拉机器人发布会“擎天柱”背后有人远程操控丨李开复:零一万物没有放弃训练大模型丨快手推出开源文生视频模型
特斯拉机器人发布会“擎天柱”背后有人远程操控丨李开复:零一万物没有放弃训练大模型丨快手推出开源文生视频模型
 阿里寻光_寻光视频创作平台_寻光视频创作官方网站
阿里寻光_寻光视频创作平台_寻光视频创作官方网站
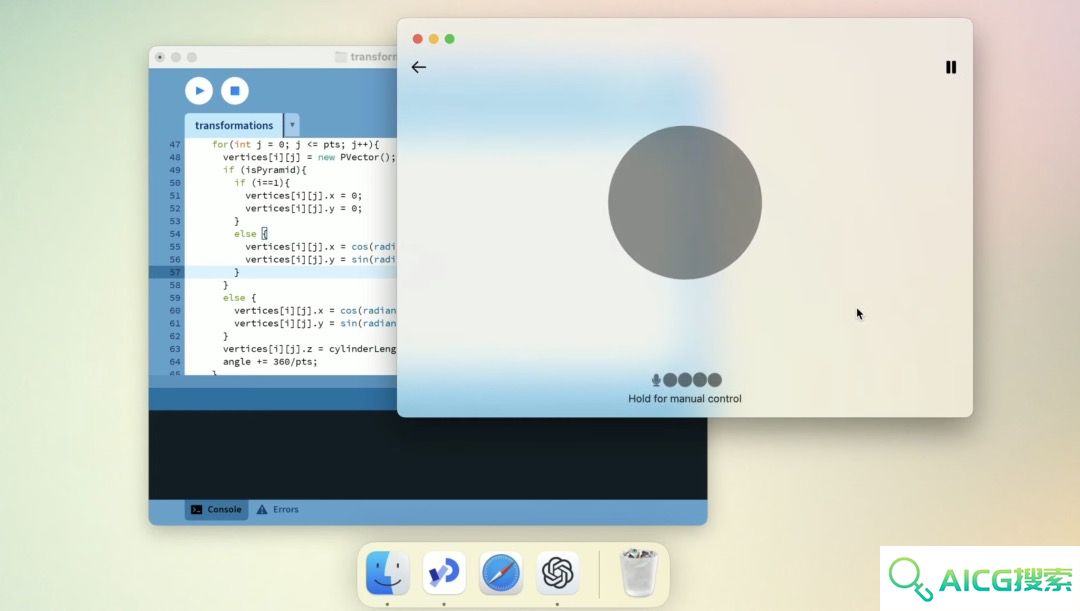 OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上
OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上
 李彦宏官宣:目前有10%的百度「大搜流量」经由文心一言大模型生成
李彦宏官宣:目前有10%的百度「大搜流量」经由文心一言大模型生成
 苹果M4芯片首发!史上最薄iPad,丝滑4K剪片:苹果发布地表最强AI硬件iPad Pro 2024款
苹果M4芯片首发!史上最薄iPad,丝滑4K剪片:苹果发布地表最强AI硬件iPad Pro 2024款