AI奇点网6月6日报道丨6月2日,来自英国剑桥大学、日本奈良先端科学技术大学院大学、腾讯AI Lab的多位研究人员们在网上公开发布了通用指令跟随大模型PandaGPT(直译过来就是:熊猫GPT)。

据介绍,PandaGPT可以执行复杂的任务,如生成详细的图像描述、编写受视频启发的故事、回答有关音频的问题。PandaGPT可同时接受多模态输入,并自然地组合它们的语义。
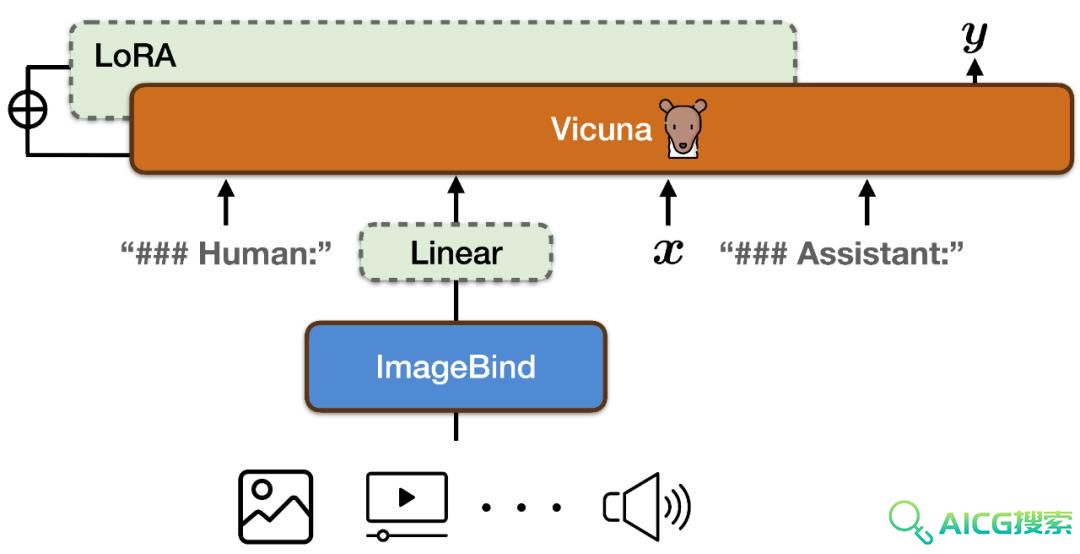
PandaGPT在文本、图像/视频、音频、深度、热度(thermal)和IMU六种模态上展示了跨模态能力,但由于ImageBind提供的共享嵌入空间,它只能使用对齐的图像-文本对进行训练。研究人员希望PandaGPT可以作为构建通用人工智能(AGI)的第一步,它可以像人类一样全面地感知和理解不同形式的输入。
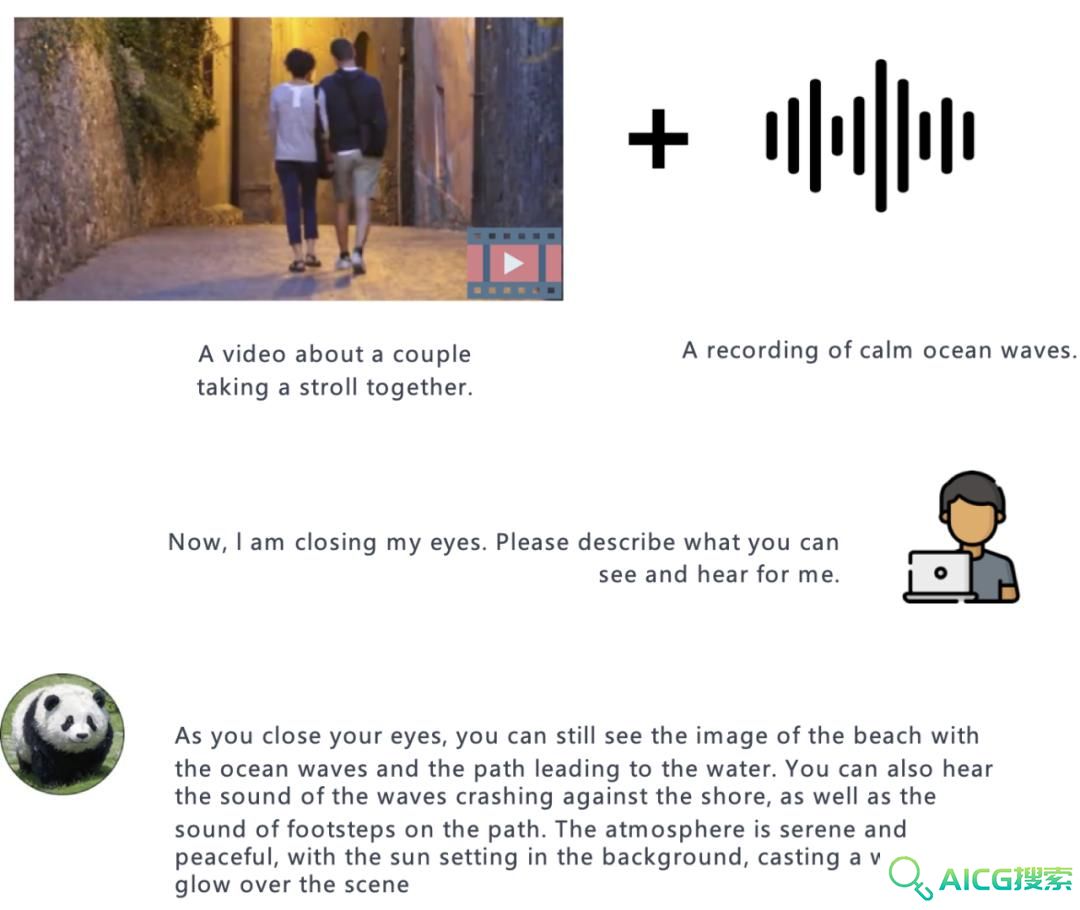
值得强调的是,目前的 PandaGPT 版本只使用了对齐的图像 - 文本数据进行训练,但是继承了 ImageBind 编码器的六种模态理解能力,具备在所有模态之间跨模态能力。在实验中,论文作者展示了 PandaGPT 对不同模态的理解能力,包括基于图像 / 视频的问答,基于图像 / 视频的创意写作,基于视觉和听觉信息的推理等等,下面其中一个例子,PandaGPT可以很好的接合图像+音频来判断一个事物:

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过 AI视频后期消除对象神器ProPainter:一涂一抹,视频轻松移除指定对象丨本地离线一键部署
AI视频后期消除对象神器ProPainter:一涂一抹,视频轻松移除指定对象丨本地离线一键部署
 特斯拉机器人发布会“擎天柱”背后有人远程操控丨李开复:零一万物没有放弃训练大模型丨快手推出开源文生视频模型
特斯拉机器人发布会“擎天柱”背后有人远程操控丨李开复:零一万物没有放弃训练大模型丨快手推出开源文生视频模型
 OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上
OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上
 李彦宏官宣:目前有10%的百度「大搜流量」经由文心一言大模型生成
李彦宏官宣:目前有10%的百度「大搜流量」经由文心一言大模型生成
 苹果M4芯片首发!史上最薄iPad,丝滑4K剪片:苹果发布地表最强AI硬件iPad Pro 2024款
苹果M4芯片首发!史上最薄iPad,丝滑4K剪片:苹果发布地表最强AI硬件iPad Pro 2024款
 美国各界如何看人工智能?
美国各界如何看人工智能?
 智源研究院:发布2025十大AI技术趋势
智源研究院:发布2025十大AI技术趋势
 Claude 3.5深夜发布_Claude 3.5体验
Claude 3.5深夜发布_Claude 3.5体验