7月21日消息,据外媒AppleInsider今晚报道,苹果公司在一篇新的研究论文中再次强调,苹果智能模型的训练并未使用任何非法从网络抓取的数据。
苹果在新发布的研究论文中表示,如果出版商不同意其数据被抓取用于训练,苹果公司将不会抓取这些数据。“我们相信,使用多样且高质量的数据来训练我们的模型是必要的。这些数据包括我们从出版商那里获得授权的数据、公开可用或开源数据集中的数据,以及通过我们的网络爬虫Applebot抓取的公开信息。”
苹果公司补充道:“我们不会在训练基础模型时使用用户的私人数据或用户交互信息。我们还采取措施应用过滤器,去除个人身份信息,排除粗俗和不安全的内容。”
论文的重点在于苹果如何执行这一抓取过程,特别是Applebot系统如何在“网络杂乱无章的环境”中确保能够获取有效信息。然而,苹果也回应了有关版权的问题,每次都重申苹果始终尊重版权持有者的权益。
从论文中获悉,苹果公司表示:“我们将继续遵循最佳的伦理抓取实践,包括遵守广泛采用的robots.txt协议,允许网页出版商选择是否让他们的内容被用于训练苹果的生成式基础模型。网页出版商对Applebot可以访问哪些页面以及如何使用这些页面拥有细致的控制,同时这些页面仍然能出现在Siri和Spotlight的搜索结果中。”
这些“精细控制”显然是基于长期使用的robots.txt系统。其并非标准的隐私保护机制,不过仍被广泛采用,网页出版商通常会在网站上放置一个名为robots.txt的文本文件。
如果AI系统看到该文件,它就应该避免抓取该站点或文件中列出的特定页面。“遵守robots.txt协议很容易,而OpenAI也曾表示它会遵守这一协议。”
论文地址
https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models_tech_report_2025.pdf

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过 五一假期全网刷屏的人气AI修图软件「Remini」实测:除了生成丑萌的黏土人,我们还发现了更多玩法
五一假期全网刷屏的人气AI修图软件「Remini」实测:除了生成丑萌的黏土人,我们还发现了更多玩法
 OpenAI CEO奥特曼强烈提议:务必尽快立法监管AI发展
OpenAI CEO奥特曼强烈提议:务必尽快立法监管AI发展
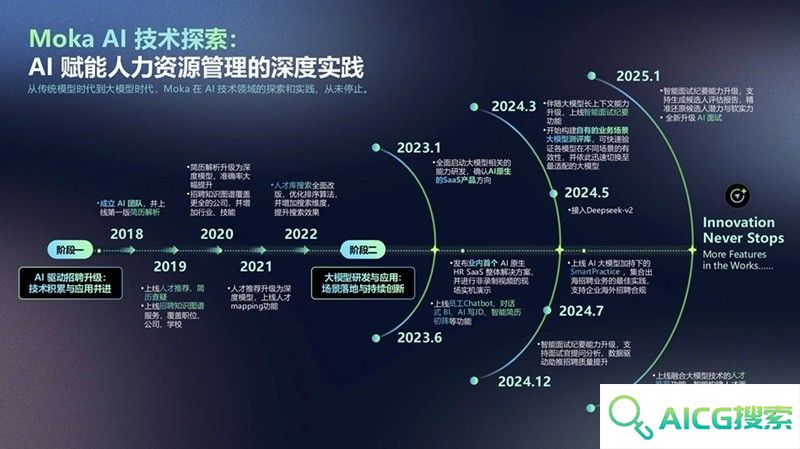 Moka AI 探索实践:七年技术深耕,从单点突破到招聘全流程闭环
Moka AI 探索实践:七年技术深耕,从单点突破到招聘全流程闭环
 神州鲲泰发布KunTai Cube「智汇魔方」:企业模型私有化部署的“全能工具箱”
神州鲲泰发布KunTai Cube「智汇魔方」:企业模型私有化部署的“全能工具箱”
 百度网盘迎来“AI时刻”:基于文心大模型,在线提供摘要及翻译
百度网盘迎来“AI时刻”:基于文心大模型,在线提供摘要及翻译
 Midjourney中文版登陆QQ频道内测:邀请中国创作者加入
Midjourney中文版登陆QQ频道内测:邀请中国创作者加入